I gorged myself on talks, panels, and tutorials last week. And parties, oh the parties. Time to digest all of it and, um, extract the most important bits. Since there is so much to talk about, I have split this up into three parts. Parts 1 and 2 will discuss individual papers and events, part 3 will add some more general observations.
VisWeek has been growing quite steadily over the last years, but this year hit a particularly interesting milestone: more than 1,000 attendees. The final number was 1,058, almost 100 more than last year.
Large-Scale Data Analysis and Visualization
The Symposium on Large-Scale Data Analysis and Visualization (LDAV) was a mixed bag. While I enjoyed Pat Hanrahan’s keynote, I was shocked when I saw the best paper. There were some redeeming papers, but the quality overall was quite low.
Rainbow colormaps are a constant source of scorn from people who care not only about putting data onto the screen, but actually being able to read the information without unnecessary distortion. The best paper at LDAV, Gaussian Mixture Model Based Volume Visualization by Shusen Liu, Joshua Levine, Peer-Timo Bremer, and Valerio Pascucci, used not just a single rainbow, but multiple ones in its color map. The effect is breathtaking.
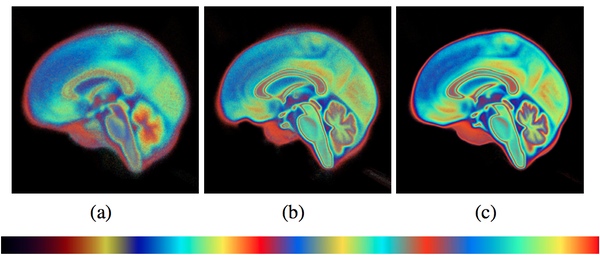
The color choice is never explained in the (very short) paper, and Shusen was quite apologetic during his presentation about the choice of color. Then why do it? I don’t get it. Whatever redeeming qualities this paper may have, it destroys information by assigning the same color to multiple values. How can this even be considered the best paper?
On the bright side, Kenneth Moreland presented his paper Redirecting Research in Large-format Displays for Visualization in a fantastic talk. He questioned the way large displays are currently built, how they are (and are not) used, and how interaction works with them. He was quite critical of the state of the art, but at the same time made concrete suggestions about how to improve the situation. One of the many interesting points he made was about the value of presenting enormous amounts of detail and our inability to find small irregularities, which came up several more times at the conference in entirely independent places (like the best paper at InfoVis).
VisWeek is already overwhelming. Instead of adding ever more sessions, I think it’s time to consider making some tough decisions. Why not cut a low-quality two-day workshop down to one day and only accept the really worthy stuff? A 53% acceptance rate drags everything down, including the good papers that make it there.
Keynote: Mary Czerwinski
A keynote is meant to inspire people and get them to think. It’s often a good idea to bring people in from somewhat different fields to talk about topics somewhat, but not entirely, unrelated to the conference.
Mary Czerwinski is a well-known researcher at Microsoft Research who has done a lot of interesting work in human-computer interaction. She gave a fine research talk, but entirely lacked any kind of big idea or inspiration. There were plenty of good starting points for some bigger ideas in her talk, too: her work on emotional state tracking could have made for some interesting and controversial points, and there were several other things that almost begged to be expanded into something bigger.
It's disappointing to see somebody of her caliber give a keynote in front of almost 1,000 people and just take the safe route of presenting her research. Luckily, the capstone made up for it.
InfoVis Best Paper
How Capacity Limits of Attention Influence Information Visualization Effectiveness by Steve Haroz and David Whitney was the deserved winner of the Best Paper award. Not only is the paper highly interesting and relevant, Haroz also gave one of the best talks all week. Instead of dwelling on small details, he presented his findings clearly and talked about concrete lessons learned from his work. Talk about basic research being useful.
The paper describes a series of experiments that looked into our ability to find outliers (unusual values) among noise, depending on whether the values around them were grouped or not. Grouping helps considerably, though there are certainly limits. Finding unusual values and patterns is a common task in visualization, so this work is quite significant. Understanding the limitations of human perception and cognition is important to know which tasks we’re actually capable of, and which we cannot do.
Among the useful advice were such things as reducing the number of colors through binning, or graying out items that are not currently of interest. Also, finding a few anomalies on an enormous display is close to impossible, as was also mentioned in Kenneth Moreland’s LDAV talk.
Soon after the presentation, a Twitter user called viscritic (whose account seems to have been deleted in the meantime) started attacking the paper on an anonymous webpage. Haroz responded by posting a brief but clear comment with some demo videos.
There was some discussion about the fact that the criticism was anonymous, but I don’t see an issue with that. The key is whether criticism is valid and fair, and whether it is delivered in a reasonable tone. Anonymous criticism should certainly be possible, even if I’d argue that it’s really not necessary in this community.
More InfoVis Papers
Design Study Methodology: Reflections from the Trenches and the Stacks by Michael Sedlmair, Miriah Meyer, and Tamara Munzner describes a framework for conducting successful design studies. While design studies are technically a paper category, they are fairly rare and often get shot down in the review process. This paper presents a great overview of successful studies as well as lessons learned from a large number of them (Tamara Munzner is probably a co-author on at least half the design studies published in InfoVis)
Visual Semiotics & Uncertainty Visualization: An Empirical Study by Alan M. MacEachren, Robert E. Roth, James O’Brien, Bonan Li, Derek Swingley, Mark Gahegan was perhaps my second-favorite paper at the conference. It describes an experiment to assess simple glyphs to display uncertainty as just three levels, rather than the quantitative approach that is usually used. Reducing the number of possible values makes it easier to understand the display and spot outliers (see Haroz above). The results of the study are not all that surprising to anybody who has done any work on uncertainty, but it’s good to see these things studied in depth. There are also broader lessons learned here about the role of semantics and categorization in visualization.
Comparing Clusterings Using Bertin’s Idea by Alexander Pilhöfer, Alexander Gribov, Antony Unwin describes a simple idea for clustering values in categorical displays such as parallel sets, Circos, and others to improve legibility. Cleaning up the visualization makes patterns much more apparent and provides another case study for Haroz’s work. Focus and decluttering seems to be something that people are realizing as important for effective visualization, and I think we’ll see more of that in the coming years.
Perception of Visual Variables on Tiled Wall-Sized Displays for Information Visualization Applications by Anastasia Bezerianos and Petra Isenberg is another look at large displays. The authors were more interested in collaboration here, but also found some interesting perceptual issues, like the fact that comparing colors over large distances is problematic, and that the lower displays tend to be much less accurate. Among the surprises is the finding that the bezels between screens can actually be useful for some tasks because they provide reference lines.
Assessing the Effect of Visualizations on Bayesian Reasoning Through Crowdsourcing by Luana Micallef, Pierre Dragicevic, and Jean-Daniel Fekete has perhaps the most intuitive explanation of Bayesian reasoning I have ever seen. The paper describes a study of visual aids for exactly this problem, but depressingly shows no effect from the visualization. It does help when there are no numbers in the accompanying text, but apparently numbers in the text make people ignore the visualization (or spend too little time on it). Both the topic of the study and the way it was set up are very interesting, and point to another huge but largely unstudied problem: how to effectively support reasoning using visualization.
A First Wrap-Up
There were some very thought-provoking papers and discussions at VisWeek this year. It’s difficult to compare, but I found the good parts to be better than in previous years. There were some really unique papers, which hopefully will be taken up as models for further work in the future.
Lane Harrison, Roman Pyzh, and Drew Skau have written up some great notes for many of the sessions, with additional comments and links.
Comments (1)
Posting new comments was disabled in 2020.