
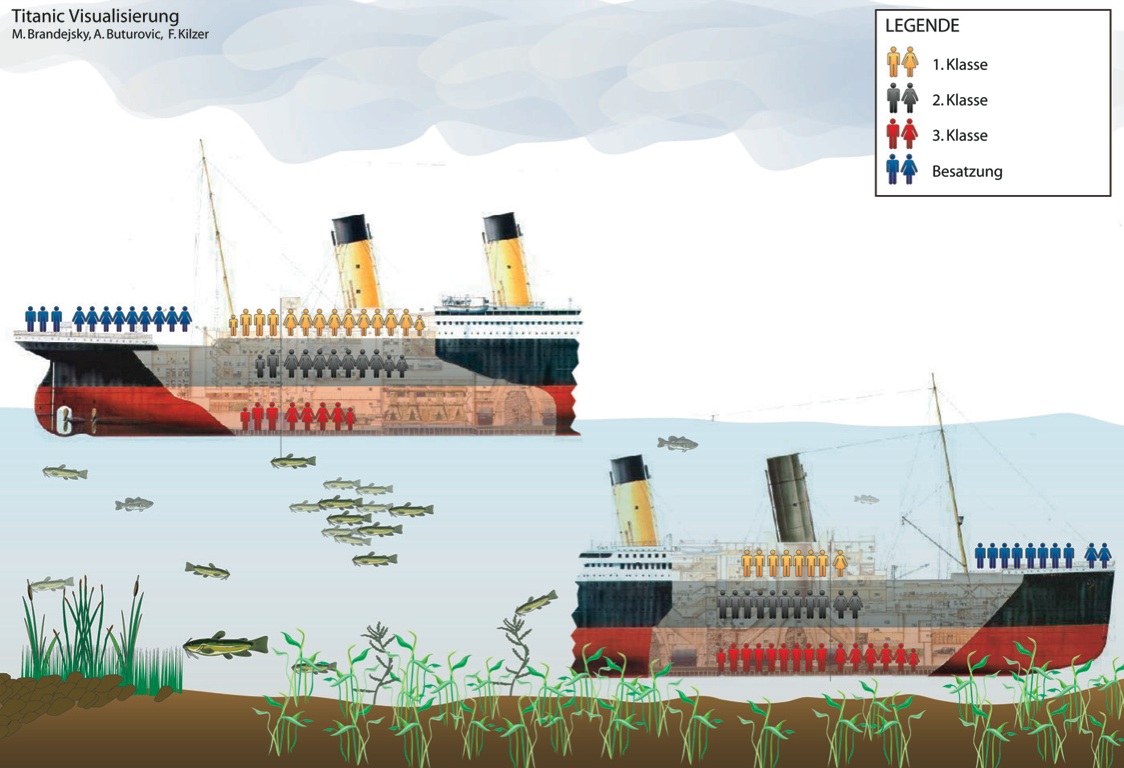
When demonstrating Parallel Sets to guests and visitors, I often use the Titanic data set, because people can relate to it and it is entirely categorical. I like pointing out interesting facts the visualization shows (like that the second class was smaller than the first class), but it's really just a collection of numbers to show what the visualization can do. Some of the people I have shown this to feel different about it, though.
Perhaps the first reaction that made me think of the Titanic as not just numbers was an artist who asked me how I could present such a horrible incident with such lovely colors. Of course I was aware that almost 1500 people died when the Titanic sank, and most of them in horrible ways. But it's also almost 100 years ago now and just so abstract and distant that it never occurred to me to be specifically sensitive about it.
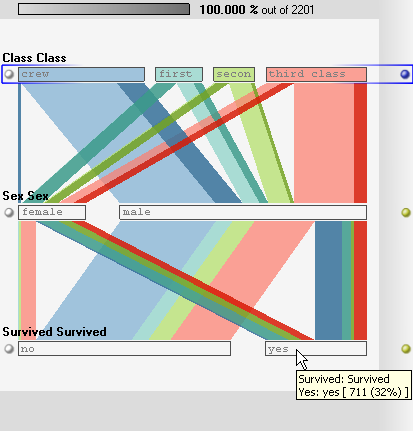
Another incident involved a Titanic buff who pointed out an error in the data: the only girl in the first class did not survive (as our data says), but rather drowned because here parents would not let her get into a life boat without them. This was another thing I was not prepared for, because first of all I assumed the data set to be correct, and second I was only using it to show off a visualization method, why would I care about the correctness of the data?
Of course, telling a good story about a data set requires understanding and interest. The impact of Hans Rosling's TED talk (which I keep linking because it has made a lot of visualization people rethink why they do what they do) comes as much from his obvious interest in the data (and its relevance) as from his presentation style and gapminder graphics. Would we care that much about a presentation that just used the data to show off the gapminder visualization?
Interesting in this regard is also Swivel's official source program, which allows organizations (like UNESCO, WHO, OECD, etc.) to publish their own data directly on Swivel, providing trustworthy data for people to scrutinize and compare with other data. Swivel's focus is clearly not visualization (and I like to chastise them for that), but the data. Is this a good approach? Not if you're only looking for the best visualization techniques, but in terms of data availability and analysis, it's an absolute necessity to build credibility and a stock of relevant and interesting data sets.

Ultimately, who cares about a visualization or a particular statistical method to figure something out? The only people who even know about John Snow's use of graphics are visualization people, but I doubt that the people cared whose lives he saved. What counts are the outcomes, not the tools that get you there.
Does that mean visualization is irrelevant? Of course not. But we need to understand the context we are working in and we must become better at telling stories about the data. The only way to do that is to care about the data we are analyzing at least as much as about the new visualization technique we developed just for it.
Comments (9)
Posting new comments was disabled in 2020.