The Winding Path of Data Analysis
Data analysis is not a straight-forward process: you try out lots of things, you go down a path that seems promising but then turns out to not work out, and suddenly you hit upon the thing you were looking for.
This comic is about mathematical proofs, but what hit me recently is how well it also applies to data analysis.
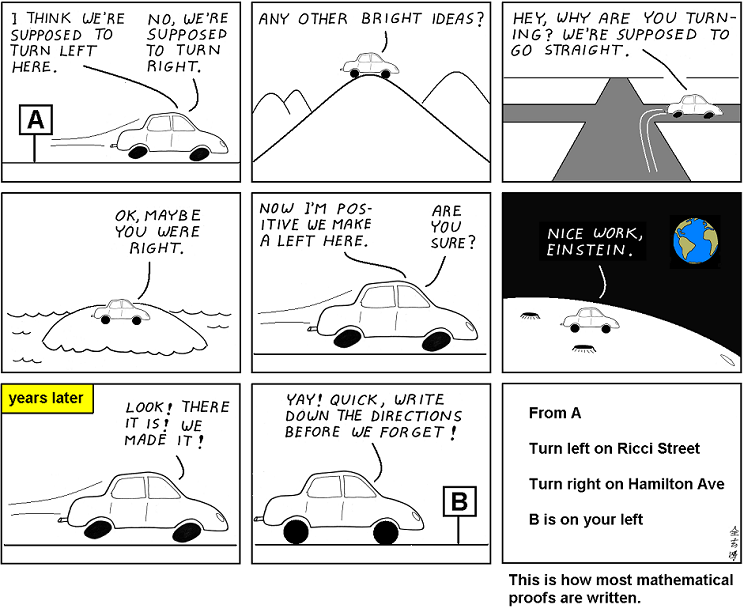
It's not just the many false starts, it also nicely shows the difference between analysis and presentation: analysis is where you make all the mistakes, but nobody cares about those. When you present your results or your insights, you show the logical, straight path. You want to present a sequence of steps that make sense, no matter whether you actually followed them during your analysis or not.
The human element here is still remarkable, and it makes me very skeptical about automated approaches. A machine might be able to try out lots of things, but how is it going to know which ones are meaningful? How is it going to tell a coherent story about its findings?
And while I get the idea of preregistration for studies, I'm not convinced that they're feasible for the same reason. There's just too much work that goes into the data analysis that is not mechanical, even without p-hacking.
Posted by Robert Kosara on October 3, 2016.